 热点资讯
热点资讯


欧洲杯体育渐渐进化出自我改良和搜索的政策-开云官网登录入口 开云app官网入口

专题:DeepSeek为何能回荡民众AI圈

来源:新智元
这些天,硅谷绝对处于中国公司带来的地面震余波中。
全好意思都在心焦:是否民众东谈主工智能的中心照旧改造到了中国?
就在这当口,民众复现DeepSeek的一波怒潮也来了。
诚如LeCun所言:‘这一次,恰是开源对闭源的得手!’
各类这些不雅点和磋磨,让东谈主不禁怀疑:数百亿好意思元开销,对这个行业竟然必要吗?以致有东谈主说,中国量化基金的一群天才,将导致纳斯达克崩盘。
从此,大模子时期很可能会插足一个分水岭:超强性能的模子不再独属于算力巨头,而是属于每个东谈主。
30好意思金,就能看到‘啊哈’时刻
来自UC伯克利博士生潘家怡和另两位预计东谈主员,在CountDown游戏中复现了DeepSeek R1-Zero。
他们暗示,禁止相等出色!
实践中,团队考证了通过强化学习RL,3B的基础话语模子也能够自我考证和搜索。
更令东谈主简洁的是,资本不到30好意思金(约217元),就可以亲眼见证‘啊哈’时刻。

这个技俩叫作念TinyZero,罗致了R1-Zero算法——给定一个基础话语模子、领导和的确奖励信号,运行强化学习。
然后,团队将其讹诈在CountDown游戏中(这是一个玩家使用基础算术运算,将数字组合以达到主义数字的游戏)。
模子从领先的肤浅输出动手,渐渐进化出自我改良和搜索的政策。
在以下示例中,模子建议了贬责决策,自我考证,并反复改良,直到贬诽谤题为止。

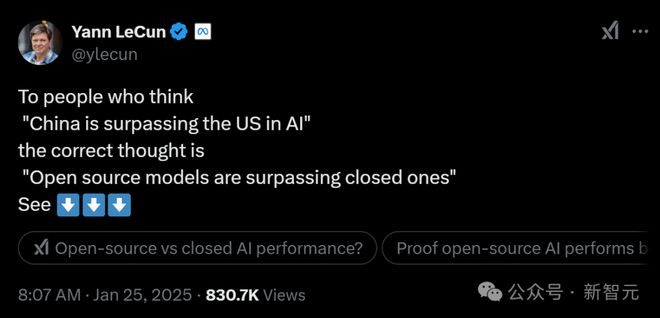
在消融实践中,预计东谈主员运行了Qwen-2.5-Base(0.5B、1.5B、3B、7B四种参数限制)。
禁止发现,0.5B模子只是是揣测一个贬责决策然后住手。而从1.5B动手,模子学会了搜索、自我考证和修正其贬责决策,从而能够赢得更高的分数。
他们觉得,在这个流程,基础模子的是性能的关节。
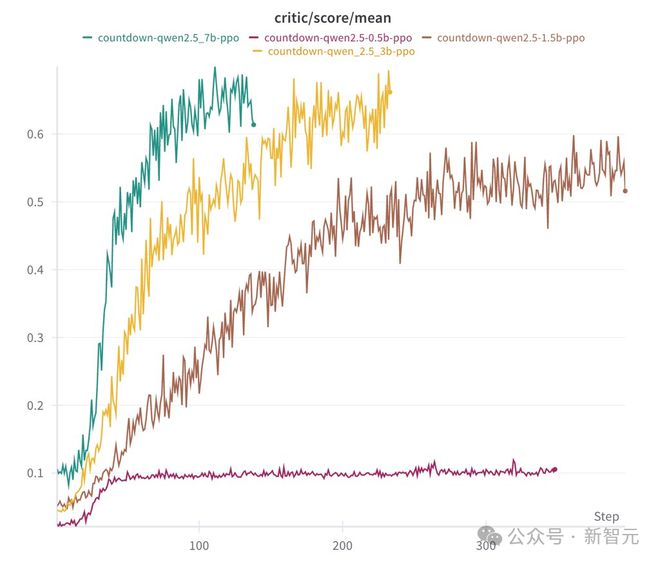
他们还考证了,迥殊的指示微调(SFT)并非是必要的,这也印证了R1-Zero的筹画决策。

这是首个考证LLM推明智商的终了可以地谈通过RL,无需监督微调的开源预计
基础模子和指示模子两者区别:
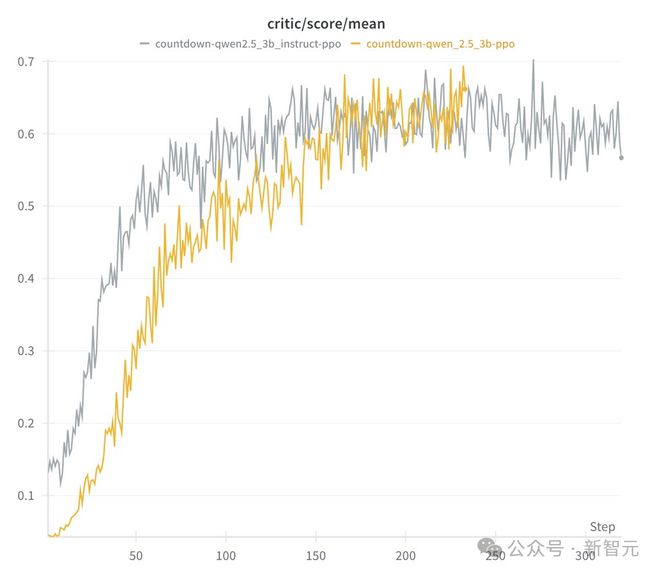
此外,他们还发现,具体的RL算法并不迫切。PPO、GRPO、PRIME这些算法中,长念念维链(Long CoT)都能够涌现,且带来可以的性能进展。
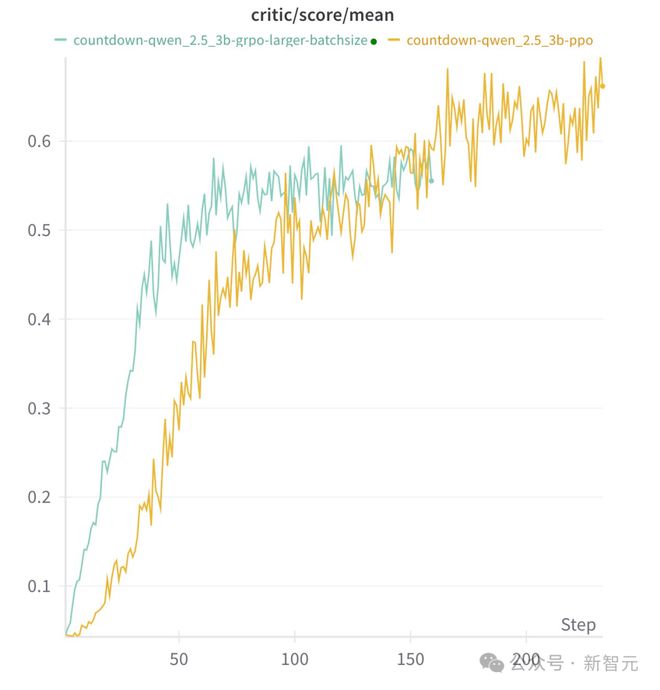
而且,模子在推理行径中特地依赖于具体的任务:
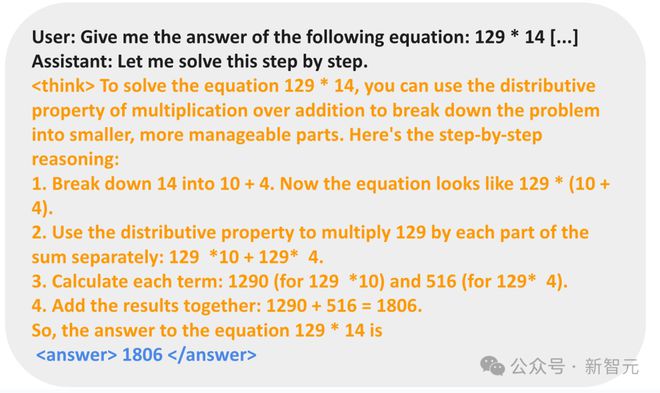
苹果机器学习科学家Yizhe Zhang对此暗示,太酷了,小到1.5B的模子,也能通过RL涌现出自我考证的智商。

7B模子复刻,禁止令东谈主诧异
港科大助理莳植何俊贤的团队(共归拢作黄裕振、Weihao Zeng),只用了8K个样本,就在7B模子上复刻出了DeepSeek-R1-Zero和DeepSeek-R1的西宾。
禁止令东谈主惊喜——模子在复杂的数学推理上取得了十分苍劲禁止。


技俩地址:https://github.com/hkust-nlp/simpleRL-reason
他们以Qwen2.5-Math-7B(基础模子)为起始,平直对其进行强化学习。
整个流程中,莫得进行监督微调(SFT),也莫得使用奖励模子。
最终,模子在AIME基准上终显然33.3%的准确率,在AMC上为62.5%,在MATH上为77.2%。
这一进展不仅杰出了Qwen2.5-Math-7B-Instruct,况且还可以和使用向上50倍数据量和更复杂组件的PRIME和rStar-MATH相比好意思!
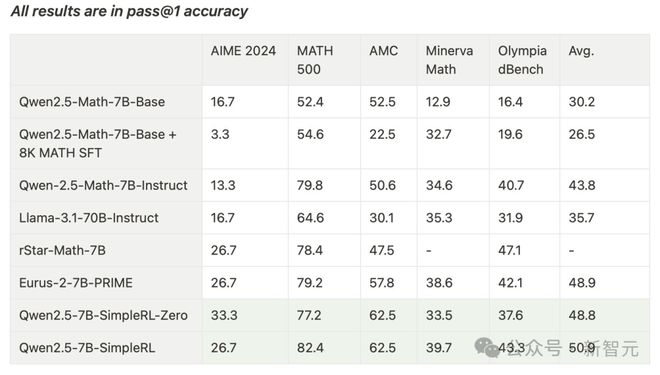
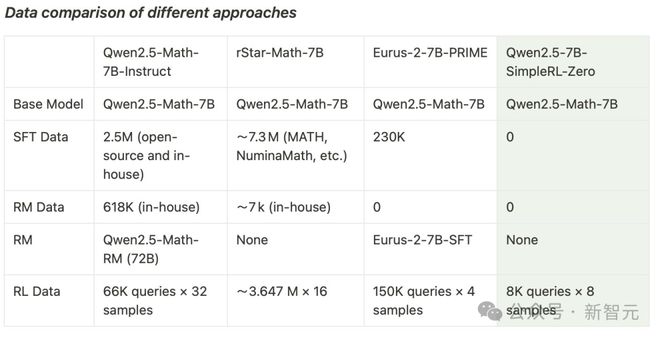
其中,Qwen2.5-7B-SimpleRL-Zero是在Qwen2.5-Math-7B基础模子上仅使用纯PPO设施西宾的,仅罗致了MATH数据纠合的8K样本。
Qwen2.5-7B-SimpleRL则起原通过Long CoT监督微调(SFT)看成冷启动,然后再进行强化学习。
在这两种设施中,团队都只使用了相通的8K MATH样本,仅此汉典。
大要在第44步的时辰,‘啊哈时刻’出现了!模子的反应中,出现了自我反念念。

况且,在这个流程中,模子还显露了更长的CoT推明智商和自我反念念智商。
在博客中,预计者防卫剖释了实践诞生,以及在这个强化学习西宾流程中所不雅察到的开心,举例长链式念念考(CoT)和自我反念念机制的自愿变成。
与DeepSeek R1访佛,预计者的强化学习决策极其肤浅,莫得使用奖励模子或MCTS(蒙特卡洛树搜索)类技能。
他们使用的是PPO算法,并罗致基于王法的奖励函数,凭据生成输出的体式和正确性分派奖励:
该终了基于OpenRLHF。初步西宾标明,这个奖励函数有助于政策模子快速照应,产生顺应守望体式的输出。
第一部分:SimpleRL-Zero(重新动手的强化学习)
接下来,预计者为咱们共享了西宾流程动态分析和一些道理的涌现模式。
西宾流程动态分析
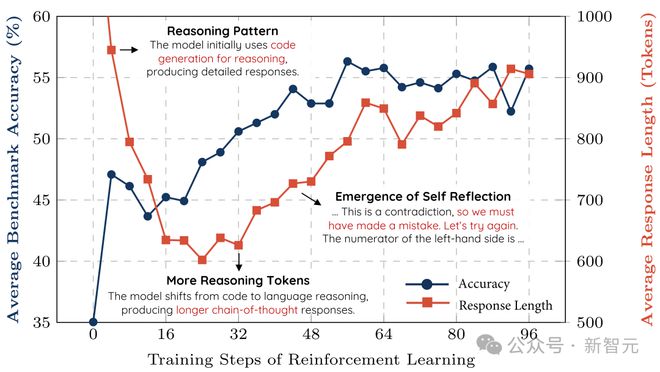
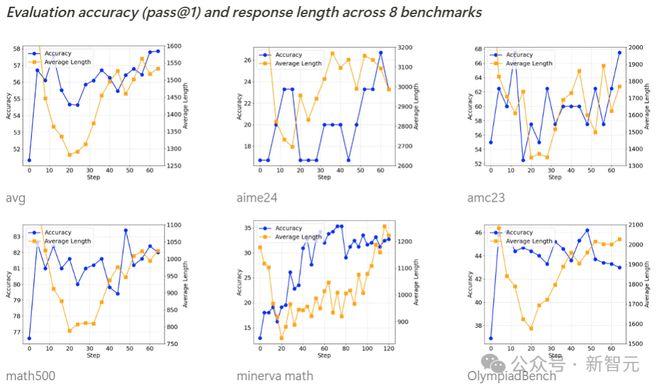
如下所示,整个基准测试的准确率在西宾流程中都在稳步提高,而输出长度则呈现先减少后逐步加多的趋势。
经过进一步访问,预计者发现,Qwen2.5-Math-7B基础模子在运转阶段倾向于生成多数代码,这可动力于模子原始西宾数据的分散特征。
输出长度的初次下落,是因为强化学习西宾逐步根除了这种代码生成模式,转而学会使用当然话语进行推理。
随后,生成长度动手再次加多,此时出现了自我反念念机制。
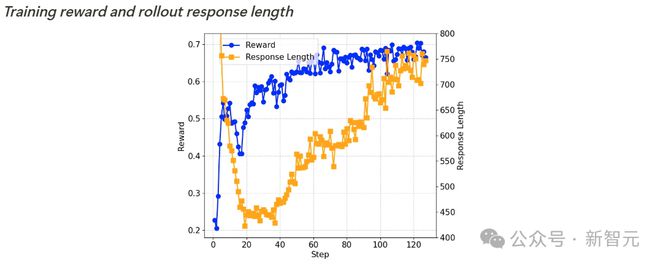
西宾奖励和输出长度
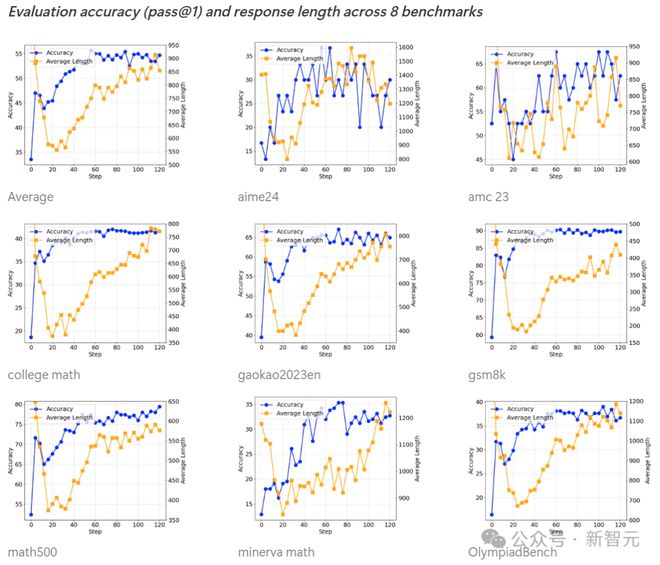
基准测试准确率(pass@1)和输出长度
自我反念念机制的涌现
在西宾到第 40 步傍边时,预计者不雅察到:模子动手变成自我反念念模式,这恰是DeepSeek-R1论文中所描绘的‘aha moment’(顿悟时刻)。

第二部分:SimpleRL(基于师法预热的强化学习)
如前所述,预计者在进行强化学习之前,先进行了long CoT SFT预热,使用了8,000个从QwQ-32B-Preview中索要的MATH示例反应看成SFT数据集。
这种冷启动的潜在上风在于:模子在动手强化学习时已具备long CoT念念维模式和自我反念念智商,从而可能在强化学习阶段终了更快更好的学习着力。
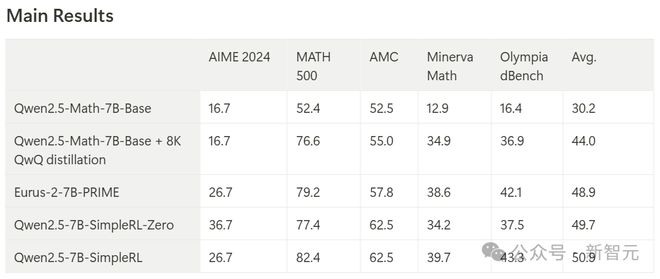
与RL西宾前的模子(Qwen2.5-Math-7B-Base + 8K QwQ常识蒸馏版块)比拟,Qwen2.5-7B-SimpleRL的平均性能显赫擢升了6.9个百分点。
此外,Qwen2.5-7B-SimpleRL不仅合手续优于Eurus-2-7B-PRIME,还在5个基准测试中的3个上杰出了Qwen2.5-7B-SimpleRL-Zero。
西宾流程分析
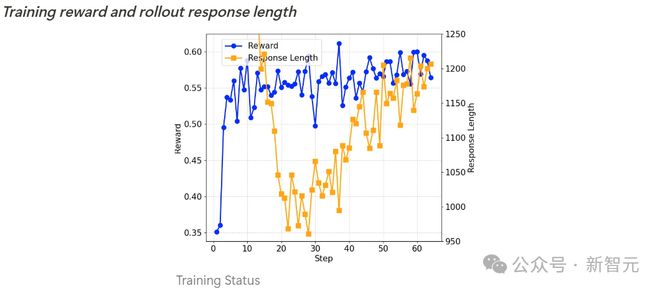
西宾奖励和输出长度
基准测试准确率(pass@1)和输出长度
Qwen2.5-SimpleRL的西宾动态进展与Qwen2.5-SimpleRL-Zero相似。
道理的是,尽管预计者先进行了long CoT SFT,但在强化学习初期仍然不雅察到输出长度减少的开心。
他们推测,这可能是因为从QwQ索要的推理模式不顺应微型政策模子,或超出了其智商鸿沟。
因此,模子聘请毁灭这种模式,转而自主发展新的长链式推理口头。
终末,预计者用达芬奇的一句话,对这项预计作念了回来——
节约,即是最终极的轮廓。

都备开源复刻,HuggingFace下场了
以致,就连民众最绽开源平台HuggingFace团队,今天官宣复刻DeepSeek R1整个pipeline。
复刻完成后,整个的西宾数据、西宾剧本等等,将整个开源。
这个技俩叫作念Open R1,刻下还在进行中。发布到一天,星标打破1.9k,斩获142个fork。
技俩地址:https://github.com/huggingface/open-r1
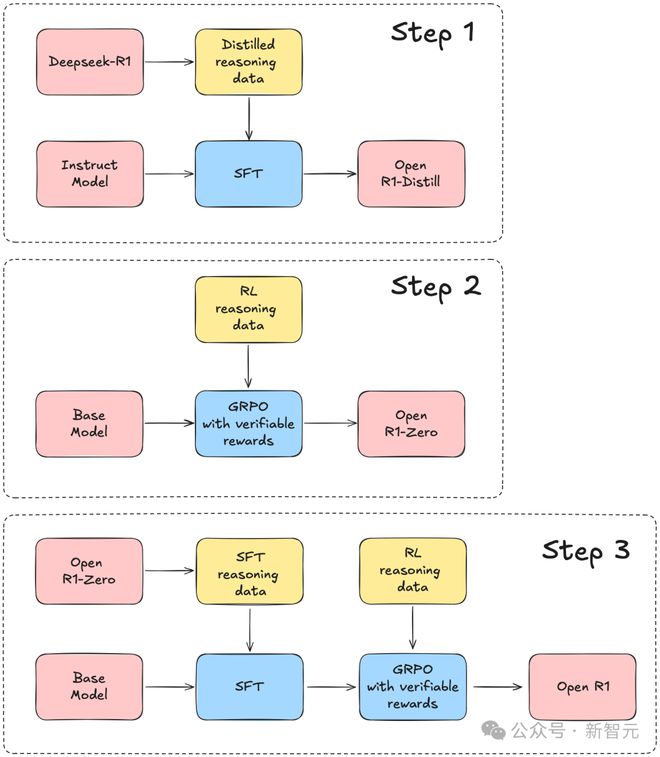
预计团队以DeepSeek-R1技能呈报为谈判,将整个复刻流程区别为三个关节设施。
从斯坦福到MIT,R1成为首选
一个副业技俩,让全寰球科技大厂为之焦躁。
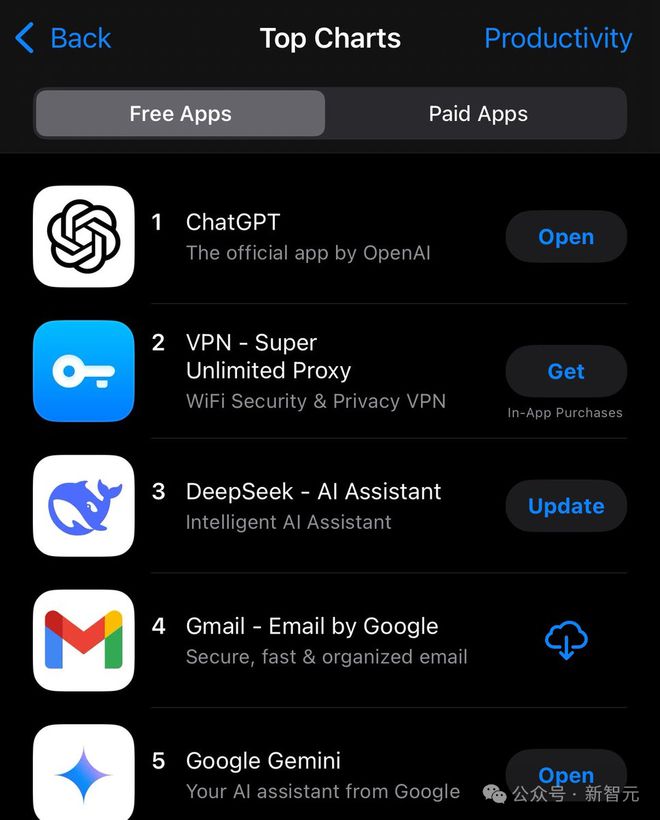
DeepSeek这波得手,也成为业界的外传,网友最新截图自大,这款讹诈照旧在APP Store‘着力’讹诈榜单中挤进前三。
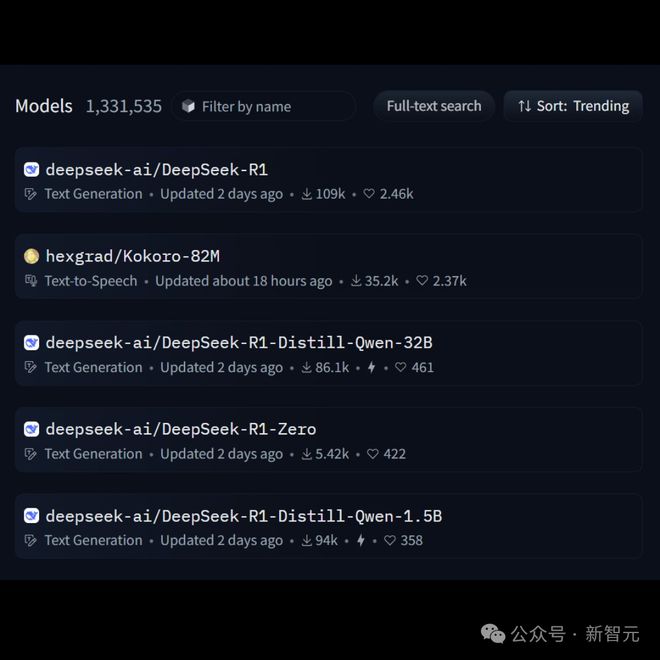
在Hugging Face中,R1下载量平直登顶,另外3个模子也抢占着热榜。
a16z结伙东谈主Anjney Midha称,通宵之间,从斯坦福到MIT,DeepSeek R1照旧成为好意思国顶尖高校预计东谈主员‘首选模子’。

还有预计东谈主员暗示,DeepSeek基本上取代了我用ChatGPT的需求。

中国AI,这一次竟然颠簸了寰球。
 海量资讯、精确解读,尽在新浪财经APP
海量资讯、精确解读,尽在新浪财经APP
背负裁剪:石秀珍 SF183欧洲杯体育