 热点资讯
热点资讯


开yun体育网条件其解读图片的中枢信息-开云官网登录入口 开云app官网入口

 智东西开yun体育网
智东西开yun体育网
智东西8月7日报谈,昨天,小红书hi lab(东谈主文智能实验室)开源了其首款多模态大模子dots.vlm1,这一模子基于DeepSeek V3打造,并配备了由小红书自研的12亿参数视觉编码器NaViT,具备多模态判辨与推理才调。
hi lab称,在主要的视觉评测集上,dots.vlm1的合座发挥已接近现时特出模子,如Gemini 2.5 Pro与Seed-VL1.5 thinking,尤其在MMMU、MathVision、OCR Reasoning等多个基准测试中显清晰较强的图文判辨与推理才调。
这一模子不错看懂复杂的图文交错图表,判辨表情包背后的含义,分析两款居品的配料表互异,还能判断博物馆华文物、画作的称呼和配景信息。

▲部分官决策例(图源:小红书技巧)
在典型的文本推理任务(如AIME、GPQA、LiveCodeBench)上,dots.vlm1的发挥大要颠倒于DeepSeek-R1-0528,在数学和代码才调上已具备一定的通用性,但在GPQA等更各种的推理任务上仍存在差距。
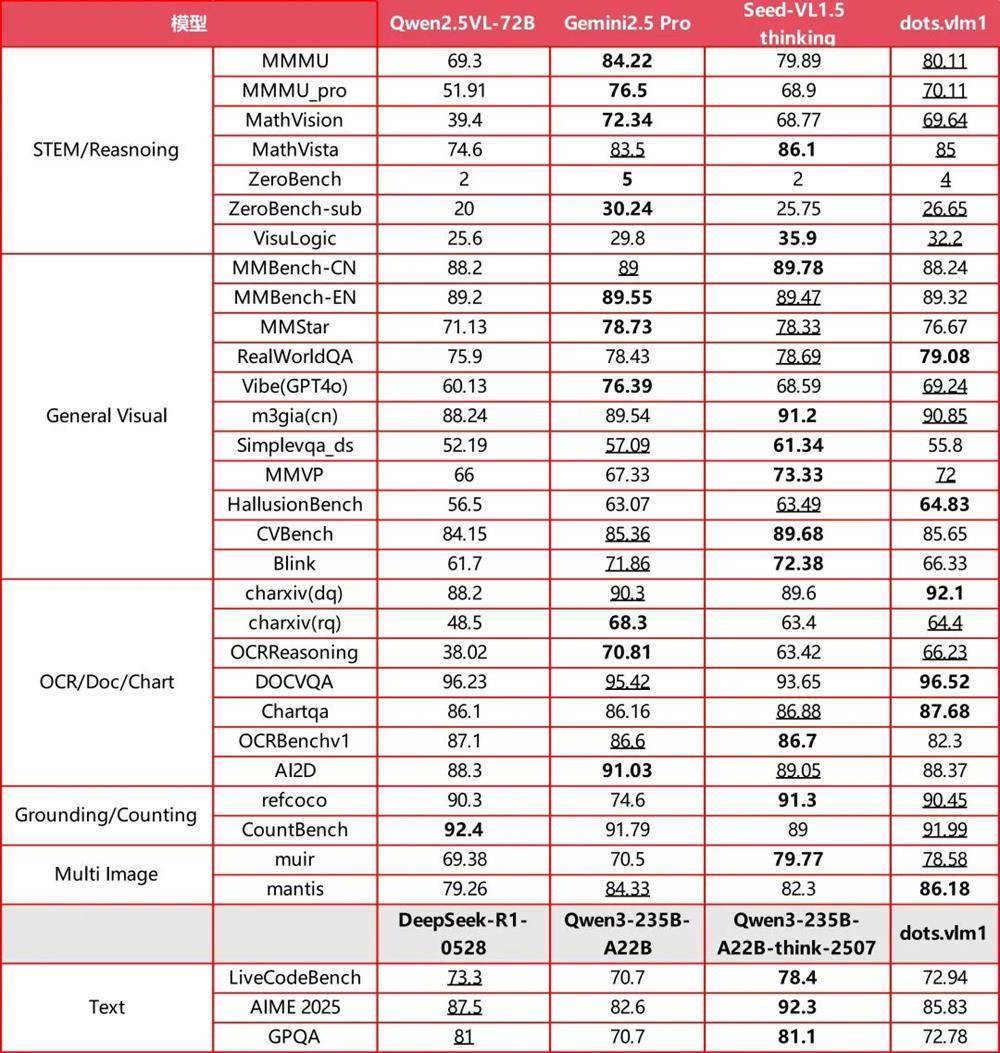
▲dots.vlm1基准测试驱散(图源:小红书技巧)
总体来看,dots.vlm1在视觉多模态才调方面已接近SOTA(最好性能)水平,在文本推理方面达到了主流模子的性能。不外,hi lab也强调,dots.vlm1在部分细分任务上仍与最优驱散存在一定距离,需要在架构联想与检修数据上进一步优化。
当今,dots.vlm1已上传至开源托管平台Hugging Face,用户还不错在Hugging Face上的体验一语气中免费使用这一模子。
本年6月6日,小红书开源了其首款诳言语模子,并在之后开源了用于OCR的专用模子,以及视觉、奖励模子等前沿标的的参议效果。这位大模子界新玩家的后续看成,值得合手续柔和。
开源地址:https://huggingface.co/rednote-hilab/dots.vlm1.inst体验一语气:https://huggingface.co/spaces/rednote-hilab/dots-vlm1-demo一、解读复杂英文图表,还能玩视觉脑筋急转弯智东西体验了dots.vlm1的多模态判辨才调。咱们将OpenAI昨日开源模子的体验网页截图上传给dots.vlm1,条件其解读图片的中枢信息。
不错看到,dots.vlm1准确识别了图中的大部分信息,还能通过阅读右侧的代码,设念念出这一代码可视化后的效果。不外,大约是由于OCR才调的问题,它将其中一款模子的参数目识别错了。

dots.vlm1具备一定的复杂图表推理才调。官方Demo案例中,dots.vlm1读懂了文本交错的英文图表,准确判辨图标元素之间的相关,并计较出了用户所问的数据。
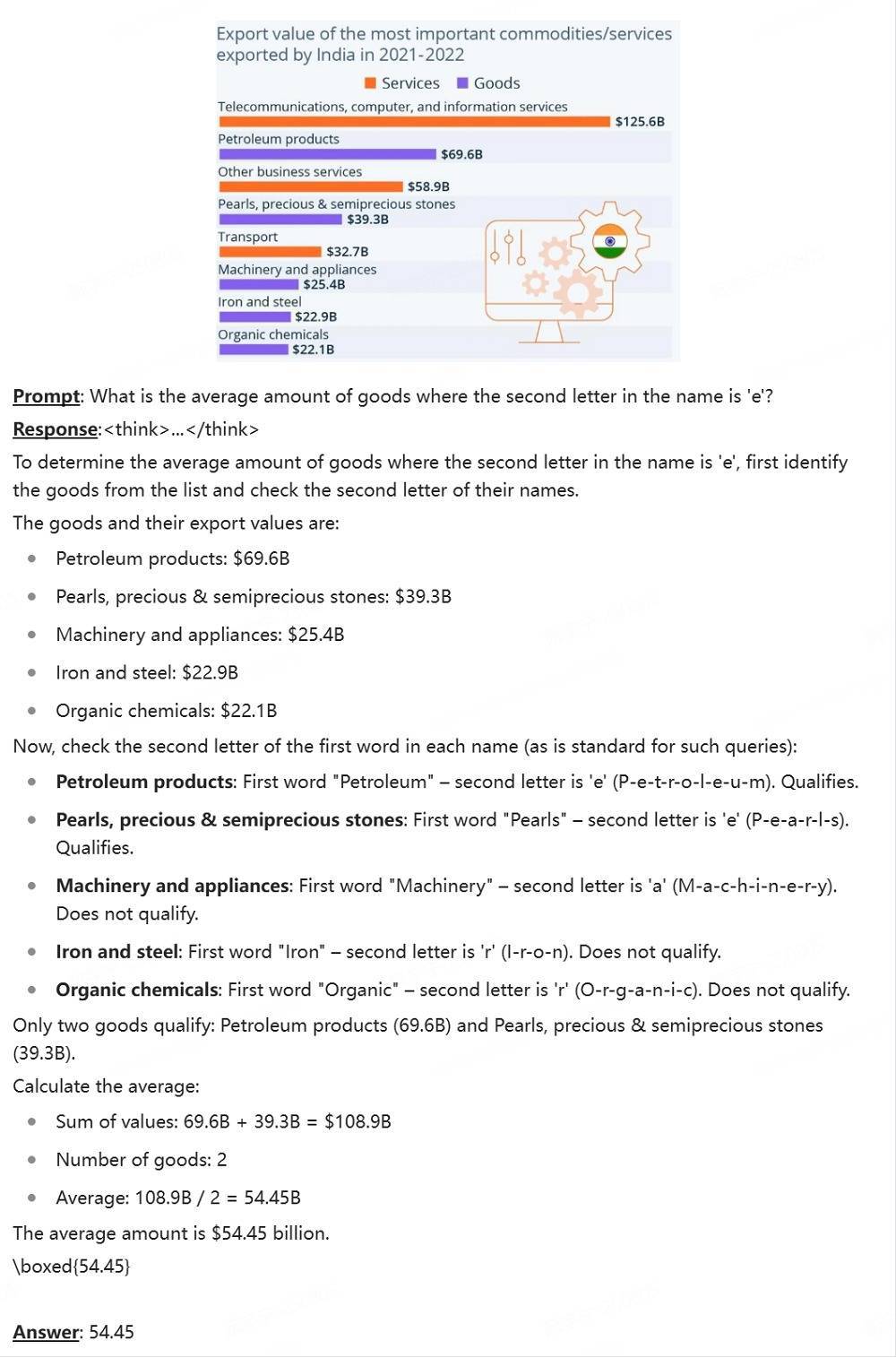
上传一张景区价目表,再辅以笔墨辅导词态状团队信息,dots.vlm1就能为用户作念好购票决策的磋磨。

数学才调方面,dots.vlm1能看懂几何题中的图形,并判辨神采等信息,凭证这些信息解题,并得出正确谜底。

dots.vlm1还能对emoji等视觉信息进行推理。举例,它凭证几个emoji所代表的形象,估计出了这一段信息代表的是《饥饿游戏前传:鸣鸟与蛇之歌》。

dots.vlm1由三个中枢组件组成:一个12亿参数的NaViT视觉编码器、一个轻量级的MLP适配器,以及DeepSeek V3 MoE诳言语模子。这一架构通过三阶段经过进行检修:
(1)视觉编码器预检修
NaViT编码器由hi lab从新检修,旨在最大化对各种视觉数据的感知才调。该编码器包含42层Transformer,采纳RMSNorm、SwiGLU和二维旋转位置编码(2D RoPE)等技巧。
预检修过程中,NaViT编码器使用双重监督战术,包括下一Token展望(NTP)和下一Patch生成(NPG)。前者通过大批图文对检修模子的感知才调,后者期骗纯图像数据,通过扩散模子展望图像patch,增强空间与语义感知才调。检修过程中使用了大批图文对。
在预检修的第二阶段,hi lab逐步逐步普及图像隔离率,从百万像素级别输入开动,在大批token上进行检修,之后升级到千万像素级别进行检修。为进一步普及泛化才调,还引入了更丰富的数据源,包括OCR场景图像、grounding数据和视频帧。
(2)VLM预检修
在这一阶段,hi lab将视觉编码器与DeepSeek V3议论检修,使用大限制、各种化的多模态数据集,主要包括跨模态互译数据和跨模态和会数据。
跨模态互译数据用于检修模子将图像实质用文本进行态状、追溯或重构,包括庸碌图像、复杂图表、表格、公式、图形、OCR场景、视频帧以及对应的文本端庄等。
跨模态和会数据用于检修模子在图文混杂凹凸文中践诺下一token展望,幸免模子过度依赖单一模态。
hi lab称,该团队为不同类型的和会数据联想了特意的清洗管线,以下两类效果尤为权贵:
网页数据:网页图文数据各种性丰富,但视觉与文本对皆质料欠安。hi lab采纳里面自研的VLM模子进行重写和清洗,剔除低质料图像和弱关联文本。
PDF数据:PDF实质质料遍及较高。为充分期骗这类数据,hi lab诞生了专用判辨模子dots.ocr(这一模子也已开源),将PDF文档飘浮为图文交错暗意。同期还将整页PDF渲染为图像,独立时遮蔽部分文本区域,指引模子取悦版面与凹凸文展望被遮蔽实质,从而增强其判辨视觉风景文档的才调。
(3)VLM后检修
hi lab通过有监督微调(SFT)增强dots.vlm1模子的泛化才调,仅使用任务各种的数据进行检修,并未采纳强化学习。
结语:感知推理才调仍有普及空间,下一步将探索强化学习hi lab称,该团队在评估中发现,dots.vlm1在视觉感知与推理才调上仍存在不及。
在视觉感知方面,hi lab联想扩大跨模态互译数据的限制与各种性,并进一步修订视觉编码器结构,探索更有用的神经蚁集架构与亏损函数联想,从而普及检修遵守。
在视觉推理方面开yun体育网,hi lab将使用强化学习设施,以减轻文本与多模态辅导在推理才调上的差距;同期也将探索把更多推理才调前置到预检修阶段的可能性,从而增强泛化性和遵守。